Airflow: Data Pipeline Tutorial
Notes on Airflow's Data Pipeline Tutorial
This tutorial demonstrated a typical ETL pipeline that downloads CSV data, does some transformation, and then loads it into a PostgreSQL database.
Hooks
It uses a PostgresHook on top of an Airflow Connection to create tables and execute queries. I had been confused about the purpose of hooks, in general. Here's something that helped me understand their purpose and value:
# Without hook - you manage everything yourself:
import psycopg2
conn = psycopg2.connect(host=..., user=..., password=...)
# Plus connection pooling, error handling, retries...
# With hook - clean and managed:
hook = PostgresHook(postgres_conn_id="my_conn")
hook.copy_expert(sql, file) # Built-in methods
Connections are kinda like phone numbers.
Hooks are like the actual phone call logic.
The Staging/Temp Table Pattern
The DAG has starts off with two tasks that run in parallel. Both use the SQLExecuteQueryOperator. One creates an employees table, and the other create a temporary employees_temp table.
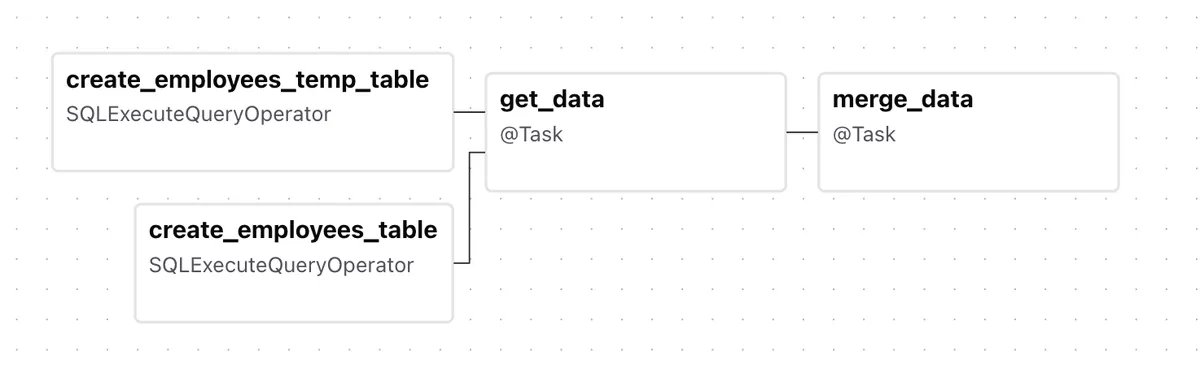
Apparently this is a very common pattern in ELT data pipelines. The temporary table is kind of like the "staging" environment, or "landing" environment. You pull the CSV data from an outside source and have it land in the temporary table because you want to polish it up (transform) before making it available to downstream consumers.
Raw Data → Temp/Staging Table → Clean/Transform → Final table
It was important for me to realize that this tutorial is showing a greenfield table. Most of the time, this pattern will be implemented on production tables that already exist. It's more about maintaining tables rather than creating them and doing the initial ingestion (as done in this tutorial).
The reality:
employeestable has millions of records and has been in production for years- Hundreds of users, dashboards, and reports query it constantly
- This pipeline runs daily to ingest new/changed employee data from HR systems
- You're usually not creating tables - you're maintaining a live, heavily-used dataset
Benefits of this pattern:
- Data validation: Check the quality before promoting it to production
- Rollback capability: You will have the raw data available in case the transformation fails or the production dataset is deleted
- Atomic operations: The ingestion and transformation happens in the staging table, and only moves to production after everything succeeds.
- Performance: The key insight is database locking. Complex operations (transforms, joins, validations) lock tables and block user queries. Staging minimizes production downtime from hours to seconds.
Without staging: Production locked for entire ETL (30+ minutes)
├── Load data: 10 minutes ⏳ (users blocked)
├── Transform: 15 minutes ⏳ (users blocked)
├── Validate: 3 minutes ⏳ (users blocked)
└── Dedupe: 2 minutes ⏳ (users blocked)
With staging: Production locked only for final merge (30 seconds)
├── Load to staging: 10 minutes ✅ (users unaffected)
├── Transform in staging: 15 minutes ✅ (users unaffected)
├── Validate staging: 3 minutes ✅ (users unaffected)
└── Quick merge to production: 30 seconds ⏳ (brief user impact)
Here's part of the get_data() function where it writes the CSV data into the employees_**temp** table:
postgres_hook = PostgresHook(postgres_conn_id="tutorial_pg_conn")
conn = postgres_hook.get_conn()
cur = conn.cursor()
with open(data_path, "r") as file:
cur.copy_expert(
"COPY employees_temp FROM STDIN WITH CSV HEADER DELIMITER AS ',' QUOTE '\"'",
file,
)
conn.commit()
The next task, merge_data() removes duplicates (SELECT DISTINCT *) from the employees_temp table and writes it to the employees (think, production) table.
def merge_data():
query = """
INSERT INTO employees
SELECT *
FROM (
SELECT DISTINCT *
FROM employees_temp
) t
ON CONFLICT ("Serial Number") DO UPDATE
SET
"Employee Markme" = excluded."Employee Markme",
"Description" = excluded."Description",
"Leave" = excluded."Leave";
"""
Just a few notes about this queries:
- This is essentially an "upsert" (update if exists, insert if not)
- The
tafter theFROMsection is an arbitrary alias for the subquery, and it required. - The
excludedkeyword is referencing a PostgreSQL virtual table containing the values that we tried toINSERTthat got blocked due to aCONFLICT.