Airflow: Dynamic DAGs
What problem(s) it solves
If you have a workflow, and you want to replicate it many many times but each one needs to be slightly different.
Without dynamic dags, you would need to have n Python files / DAGs, where n is the number of variations of the workflow.
This can become very verbose, lots of duplication, and hard to maintain.
It basically makes a DAG like a reusable function.
Implementation
The Single File Method
Generating DAGs by using a loop:
# This is the DAG generator function. It returns a DAG.
def create_dag(filename):
with DAG(f'process_{filename}', start_date=datetime(2021,1,1), schedule_interval='@daily', catchup=False) as dag:
@task
def extract(filename):
return filename
@task
def process(filename):
return filename
@task
def send_email(filename):
print(filename)
return filename
send_email(process(extract(filename)))
return dag
# This is where you call the DAG generation function using a loop
for f in ["file_a.csv", "file_b.csv", "file_c.csv"]:
# You can't just call the function.
# create_dag(f)
# You have to do it this way because Airflow registers DAGs in the `globals` environment
globals()[f"dag_{f}"] = create_dag(f)
Pros:
- Pretty simple. Adding a new DAG would just be appending to the loop list.
Cons:
- No visibility on the generated DAGs. If you look at the code in the UI it'll just show the DAG generation file, and you obviously don't have the individual files on your file system. This could make it harder to debug DAGs.
- DAGs are generated every
min_file_process_interval, so the DAGs will be generated every 30 seconds and the scheduler has to parse through all of that. Might put a strain on the scheduler. - Need to remove the DAG from the metastore if you remove it from you generation loop!
Multi-file Method
The idea is that you have a template file with placeholder values, config files (data/___.json in the example below) for each dag, and a script to fill in the placeholder values.
❯ tree include
include
├── data
│ ├── file_a.json
│ ├── file_b.json
│ └── file_c.json
├── scripts
│ └── generate_dag.py
└── templates
└── process_file.py
An admin would just run the script and the deploy the changes. It is idempotent, in theory, and you can enforce that within the script. You could also enhance the script to remove dags from the metastore that were deleted.
Pros:
- Clear visibility. Individual files. New files can be generated easily using parameters.
Notes
Dynamic DAGs should not be confused with Dynamic Task Mapping.
Dynamic DAGs -> Create DAGs based on predefined values
Dynamic Task Mapping -> Create tasks based on unknown values from previous tasks' output
For the "single-file" method, you can create DAGs by registering them with the globals Python context:
for f in ["file_a.csv", "file_b.csv", "file_c.csv"]:
globals()[f"dag_{f}"] = create_dag(f)
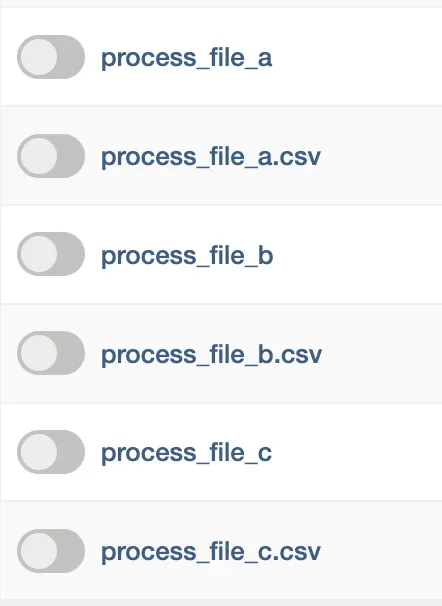
One thing that isn't great about this, is that if you change the name of the arguments in the list, the old DAGs will still appear in the metastore and UI. In the screenshot below, I changed file_a to file_a.csv and the file_a DAG still exists. It might get cleaned up when the DAG parser runs, but the DAG still remains in the metastore!