Airflow: Datasets
Source material:
Seems like Datasets will be deprecated eventually, in favor of Assets.
Datasets work within the same Airflow deployment (e.g., not across different deployments).
Datasets are a tool for data-driven scheduling and can replace the TriggerDagRunOperator and ExternalTaskSensor
This image depicts a monolithic DAG being broken down into three smaller, loosely-coupled DAGs that produce and consume Datasets:
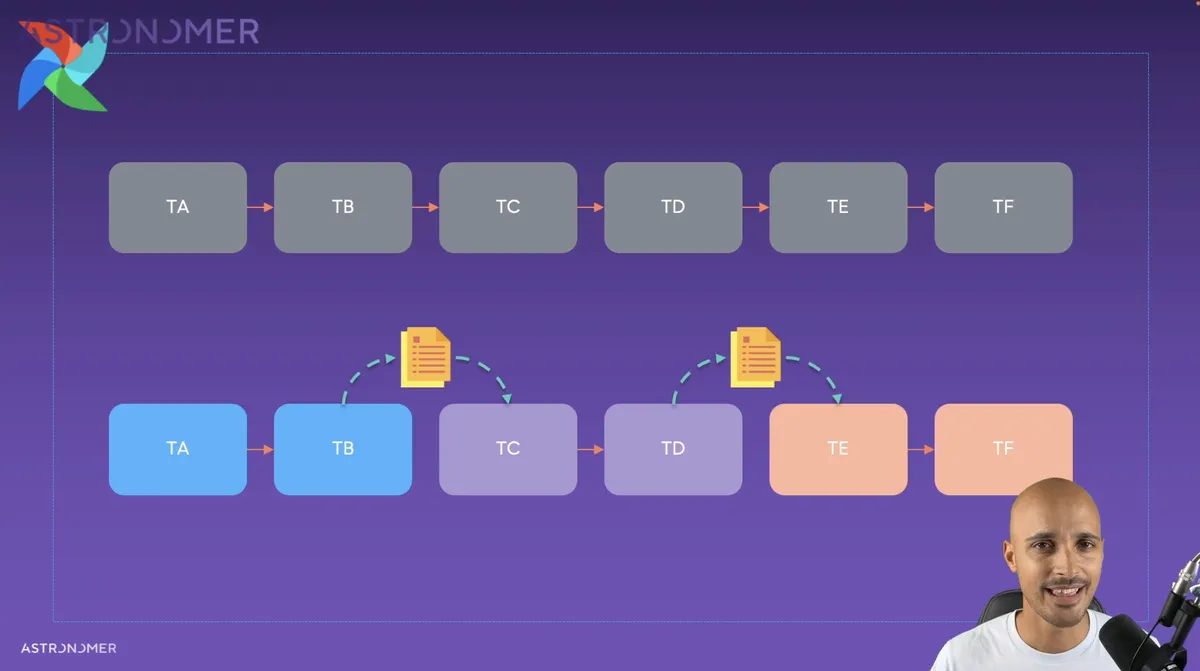
Benefits of a more loosely-coupled set of DAGs vs a monolithic DAG:
- Having data products arrive on time. The more tasks in a DAG, the longer the DAG will take to run (generally speaking), and therefore might delay the landing of the product.
- A monolithic DAG might have multiple people working on it, which can create conflicts. Smaller DAGs can be owned by individuals.
Dataset: A data object that references a resource such as a file or table.
What counts as an update to a dataset?
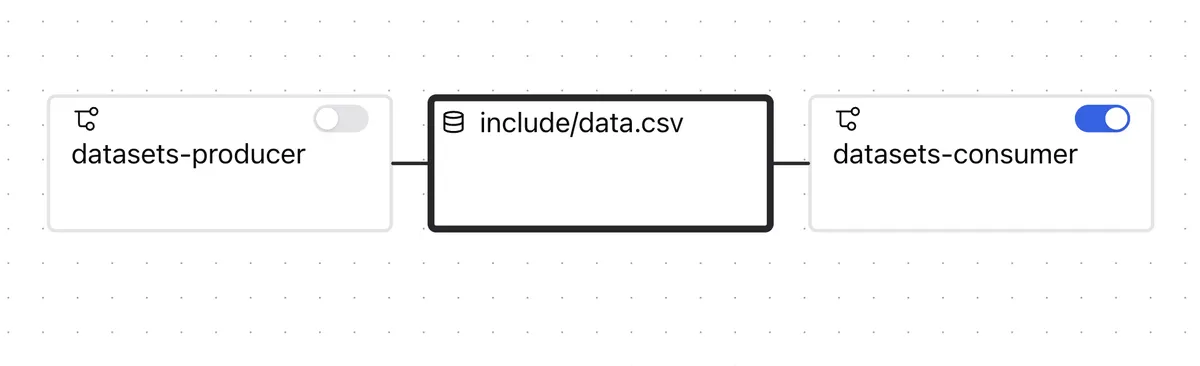
This image shows two dags (consumer and producer) that share a dataset. The producer updates it, and that event triggers the consumer dag. In this case, the dataset is a csv file that is on the host's file system.
I tried to exec into the scheduler container (I'm running Airflow locally via astro), and manually update the file. The producer DAG did not get triggered.
Why not? Because "watching" files or S3 paths or database tables would require something like polling or server-side events that would use a lot of resources (not scalable).
Instead (at least, I think this is how it works), the upstream DAG (consumer), sets the dataset as an outlet of the task:
with DAG(
dag_id="producer",
...
):
@task(outlets=[my_dataset]) # -> the dataset will be officially "updated" upon success
def update_dataset():
with open(my_dataset.uri, "a") as file:
file.write(f"producer updates at {datetime.now()}"
So manually editing the dataset bypasses the context of Airflow and therefore doesn't consider it to have been updated. The consumer can only be triggered by the producer.
The producer doesn't even need to actually update the dataset. As long as the function succeeds, the consumer will be triggered.
Datasets / Assets shine when there is a shared dataset between two operations and it gets updated in an irregular timing pattern.
The TriggerDagRunOperator might be better if the "producers" are running tests on their asset before passing it downstream. If you want to do testing or validation before shipping downstream.
The ExternalTaskSensor might me a better choice if you want to trigger specific tasks instead of entire DAGs